
What is a good balanced accuracy score? Simply explained
Balanced accuracy is a machine learning error metric for binary and multi-class classification models. It is a further development on the standard accuracy metric but is adjusted such that it can perform better on imbalanced datasets
What is balanced accuracy?
Balanced accuracy is a machine learning error metric for binary and multi-class classification models. It is a further development on the standard accuracy metric whereby it's adjusted to perform better on imbalanced datasets, which is one of the big tradeoffs when using the accuracy metric. It is therefore often seen as a better alternative to standard accuracy.
How does balanced accuracy work on imbalanced datasets?
As mentioned above, balanced accuracy is designed to perform better on imbalanced datasets than it's simpler cousin, accuracy. But how does it do this?
We can learn a bit more by looking at how balanced accuracy is defined:
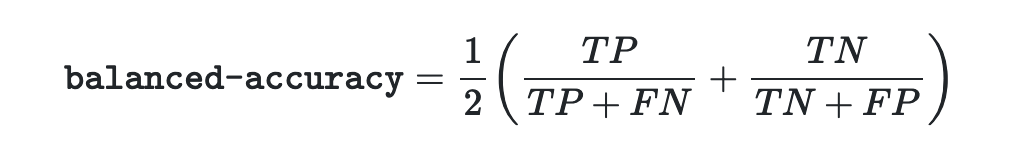
What this definition shows us is that, for binary classification problems, balanced accuracy is the mean of Sensitivity and Specificity. Where Sensitivity (True Positive Rate) is the probability of a positive case being accurately classed as being positive, and Specificity (True Negative Rate) is the probability of a negative case being accuracy classed as negative. This is the secret sauce that helps the metric perform well for imbalanced datasets.
Using the average of Sensitivity and Specificity, we are able to account for imbalanced datasets as a model will receive a worse balanced accuracy score if it only predicts accurately for the majority class in the dataset.
What is a good balanced accuracy score?
As with all metrics, a good score is entirely dependent upon your use case and dataset. A medical use case will often have a higher threshold than real estate for example. However, there is a general rule of thumb that many data scientists will stick to.
Much like accuracy, balanced accuracy ranges from 0 to 1, where 1 is the best and 0 is the worst. So a general rule for 'good' scores is:
- Over 0.9 - Very good
- Between 0.7 and 0.9 - Good
- Between 0.6 and 0.7 - OK
- Below 0.6 - Poor
How do I calculate balanced accuracy in Python?
Balanced accuracy is simple to implement in Python using the scikit-learn package. An example of using balanced accuracy for a binary classification model can be seen here:
from sklearn.metrics import balanced_accuracy_score
y_true = [1,0,0,1,0]
y_pred = [1,1,0,0,1]
balanced_accuracy = balanced_accuracy_score(y_true,y_pred)When should I use balanced accuracy vs accuracy?
During this post I have often referred to the similarity between accuracy and balanced accuracy, but how do you know when to use accuracy and when to use balanced accuracy?
If you had to choose between using just one of accuracy or balanced accuracy then I would always recommend using balanced accuracy. This is due to the fact that both of these error metrics will perform in the same way when you have a balanced dataset, but when the classes aren't balanced then balanced accuracy performs much better than accuracy, for the reasons discussed above.
Therefore, there is no reasonable situation that could arise where accuracy would be a better choice, other than perhaps name recognition amongst end users.
Related articles
Classification metrics
What is a good F1 score?
What is a good AUC score?
Classification metrics for imbalanced data
Confusion matrix calculator
Classification metric comparisons
AUC vs accuracy
F1 score vs AUC
F1 score vs accuracy
Micro vs Macro F1 score
References

