Catboost vs XGBoost
This post outlines the differences between two popular gradient boosting machine learning models, XGBoost and Catboost.
1. What is gradient boosting?
2. What is XGBoost?
3. What is Catboost?
4. What are the similarities?
5. What are the differences?
6. When should I use them?
7. Which is better?
What is gradient boosting?
Both of these models are gradient boosting models, so let's have a quick catch-up on what this means.
Gradient boosting is a machine learning technique where many weak learners, typically decision trees, are iteratively trained and combined to create a highly performant model. The decision trees are trained sequentially and use the error from the previous tree to adjust its learning and eventually minimise the loss function.
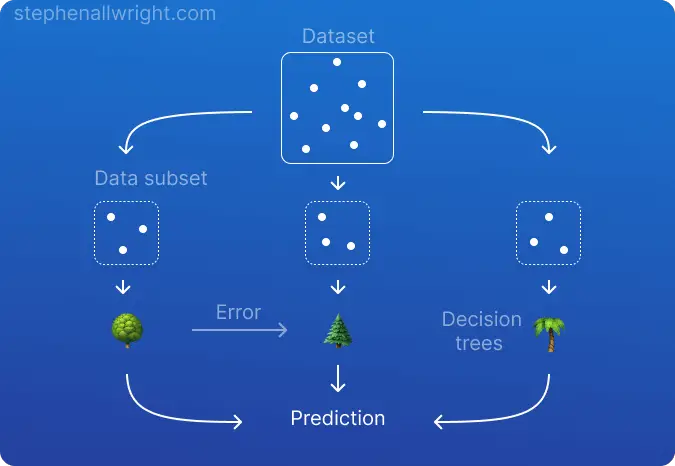
What is XGBoost?
XGBoost is a gradient boosting machine learning algorithm that can be used for classification and regression problems.
Like all gradient boosting models, it is an ensemble model which trains a series of decision trees sequentially but it does so in a level-wise (aka. horizontally) fashion. In this horizontal sequential training, each decision tree is shallow but the number of trees is many (by default).
XGBoost is designed to be a general all-purpose gradient boosting model which performs well out-of-the-box for most datasets.
What is Catboost?
Catboost is also a gradient boosting machine learning algorithm that can be used for classification and regression problems.
It too is a highly performant model out-of-the-box, but there are a few key features that make Catboost unique. Chief among these is its ability to handle categorical features and text features without having to undertake pre-processing to convert them to numerical features first.
What are the similarities between Catboost and XGBoost?
- Model framework. Both use the gradient boosting method to train many weak decision trees in an ensemble model
- Performance. Both models perform very well out of the box with standard parameters on most datasets
- Use case. They can be used for classification and regression
- Datasets. Both can handle large datasets with ease
What are the differences between Catboost and XGBoost?
- Training time. Catboost is consistently faster to train and predict than XGBoost, which is notoriously slow to use
- Categorical and text data. Catboost can handle categorical and text data without pre-processing, whilst XGBoost requires them to be encoded numerically beforehand
- Null values. Catboost handles null values without the need for pre-processing, whilst XGBoost needs them to be dealt with before training
- Regularization. Catboost uses ordered boosting for regularisation, whilst XGBoost uses L1 or L2
- Overfitting. Due to Catboost's use of ordered boosting for regularisation, it is much less prone to overfitting on training datasets
When should you use Catboost or XGBoost?
Both Catboost and XGBoost are well performing boosting models, but when you should use one or the other depends upon your dataset and technical constraints.
As a rough rule of thumb, I would suggest:
- Use Catboost when you have a significant number of categorical or text features
- Use XGBoost if you have a mix of features types and you do not have many technical constraints for the deploying of your model
Catboost vs XGBoost, which is better?
Which model is better depends primarily upon your dataset, where the more categorical variables you have the more reason there is to choose Catboost.
However, if you are unable to decide between the two based on your dataset needs then it is generally recommended to use XGBoost. This is because it works well on a wider range of datasets, is highly tuneable, and is extremely well documented online if you ever need help.
Related articles
What is a baseline machine learning model?
Model choice
Random Forest vs XGBoost
XGBoost vs LightGBM
Catboost vs LightGBM
References

