
What is the difference between cross_val_score and cross_validate?
Cross_val_score and cross_validate are cross validation functions in the sklearn package, but which should you use? In this post I will explore what they are, their differences, and which you need for your project.
Cross_val_score and cross_validate are cross validation functions in the sklearn package, but which should you use? In this post I will explore what they are, their differences, and which you need for your project.
What are cross_val_score and cross_validate?
Cross_val_score and cross_validate are functions in scikit-learn which run the cross validation process over a dataset. Cross validation is the process of training and testing a machine learning model over multiple folds of the same dataset, instead of a single train/test split as is commonly done. This approach gives you a better understanding as to whether the model generalises over the whole dataset or not.
An illustration of how this typically works is shown here:
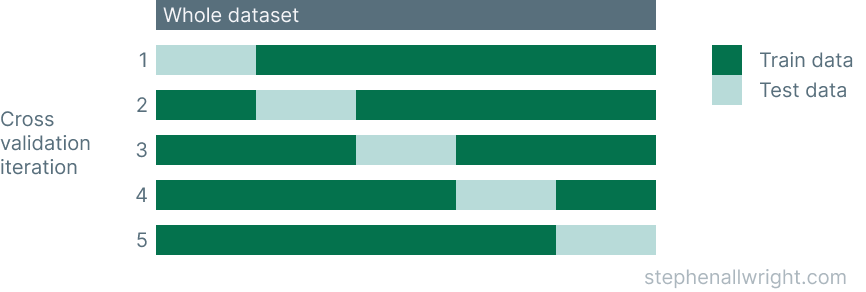
What is the difference between cross_val_score and cross_validate?
Cross_val_score and cross_validate have the same core functionality and share a very similar setup, but they differ in two ways:
- Cross_val_score runs single metric cross validation whilst cross_validate runs multi metric. This means that cross_val_score will only accept a single metric and return this for each fold, whilst cross_validate accepts a list of multiple metrics and will return all these for each fold.
- Cross_validate returns extra information not found in cross_val_score. In addition to the test scores, cross_validate also returns the fit times and score times.
How can you implement cross_val_score and cross_validate in Python?
Both these functions are simple to implement in Python, but first let’s look at how these functions fit into a typical machine learning development workflow:
- Create a dataset
- Run hyper-parameter tuning
- Create model object with desired parameters
- Run cross_val_score or cross_validate on dataset to test model performance
- Train final model on full dataset
Therefore, in order to use these two functions we need to first have an idea of the model we want to use and a prepared dataset to test it on. Let’s look at how this process would look in Python:
from sklearn import datasets
from sklearn.model_selection import cross_validate, cross_val_score
from sklearn.linear_model import LinearRegression
X, y = datasets.load_diabetes(return_X_y=True)
model = LinearRegression()
# Running cross_validate with multi metric
metrics = ['neg_mean_absolute_error', 'r2']
scores = cross_validate(model, X, y, cv=5, scoring=metrics)
mae_scores = scores['test_neg_mean_absolute_error']
r2_scores = scores['test_r2']
print("Mean mae of %0.2f with a standard deviation of %0.2f" % (mae_scores.mean(), mae_scores.std()))
print("Mean r2 of %0.2f with a standard deviation of %0.2f" % (r2_scores.mean(), r2_scores.std()))
# Running cross_val_score with single metric
scores = cross_val_score(model, X, y, cv=5, scoring='neg_root_mean_squared_error')
print("Mean score of %0.2f with a standard deviation of %0.2f" % (scores.mean(), scores.std()))
Should I use cross_val_score or cross_validate?
The choice of whether to use cross_val_score or cross_validate comes down to one factor, whether or not you want to return one or multiple metrics for each fold. If you need multiple metrics then you should use cross_validate, however if you only need one then cross_val_score may suffice. In general though, cross_validate is the most commonly used function as it provides much more flexibility than cross_val_score, so I would recommend using that.
Related articles
Fix sklearn.cross_validation import error
References
cross_validate documentation
cross_val_score documentation
Cross validation guide from sklearn

